
The Event: Data Engineering for AI/ML
At the Data Engineering for AI/ML event, hosted by the MLOps.Community in September 2024, engineers and data practitioners discussed their challenges and solutions in areas such as data orchestration frameworks (e.g., Apache Airflow) and scalable data platforms for Machine Learning and AI. A key focus was on achieving balance between centralized data reliability and decentralized data ownership, as highlighted in Stephen Bailey’s session, which examined Whatnot’s journey toward providing machine learning, business intelligence, and real-time analytics services.
YouGot.us worked with the MLOps.Community event participants and YouGot.Us MLOps panel audiences and asked them about practical data tools and methodologies required to design, deploy, and maintain robust AI and Machine Learning pipelines at scale.
Introduction and Methodology
The survey was organized by Christina Stein from the YouGot.us Research Project and Demetrious Brinkmann, Founder of the MLOps Community, as part of the Data Engineering in AI event. The objective was to investigate the current trends in Data and ML tools used by professionals to implement and scale AI/ML pipelines. The survey was conducted online using a Computer-Assisted Web Interview (CAWI), chosen for its efficiency and ability to reach a broad audience during the two-day event.
The questionnaire was structured into sections: (1) General Demographics, (2) Experience with Programming and Machine Learning, (3) Adoption of Data and ML Orchestration Tools, and (4) Team Dynamics in AI/ML Projects. A screener question was included to filter respondents actively working in data, AI, or ML fields, ensuring the data collected reflects relevant professional experiences.
The survey aimed to identify the tools and practices employed by engineers in scaling AI/ML systems, challenges in orchestration, and team collaboration. The study also sought to explore the technologies currently in use, any roadblocks encountered, and how teams approach the implementation of data engineering and ML workflows.
Limitations
This survey is exploratory in nature and does not purport to be a scientifically rigorous or representative sample of the MLOps engineering market. Its primary purpose is to provide an initial framework for future, more comprehensive studies. A notable limitation of this research is the response rate. Between September 12th and October 12nd, we collected a total of 214 responses, excluding 2 test submissions that were discarded.
Job Roles in Data Engineering for AI and ML
Data Engineers and Data Scientists make up the largest share of roles in AI and ML projects, according to a survey conducted by YouGot.us in collaboration with the MLOps Community. The survey, conducted online in September 2024, gathered responses from 204 participants. Data Engineers account for 21.1% of respondents, while Data Scientists represent 14.7%. Other notable roles include Machine Learning Engineers (8.8%) and Software Engineers (7.8%).
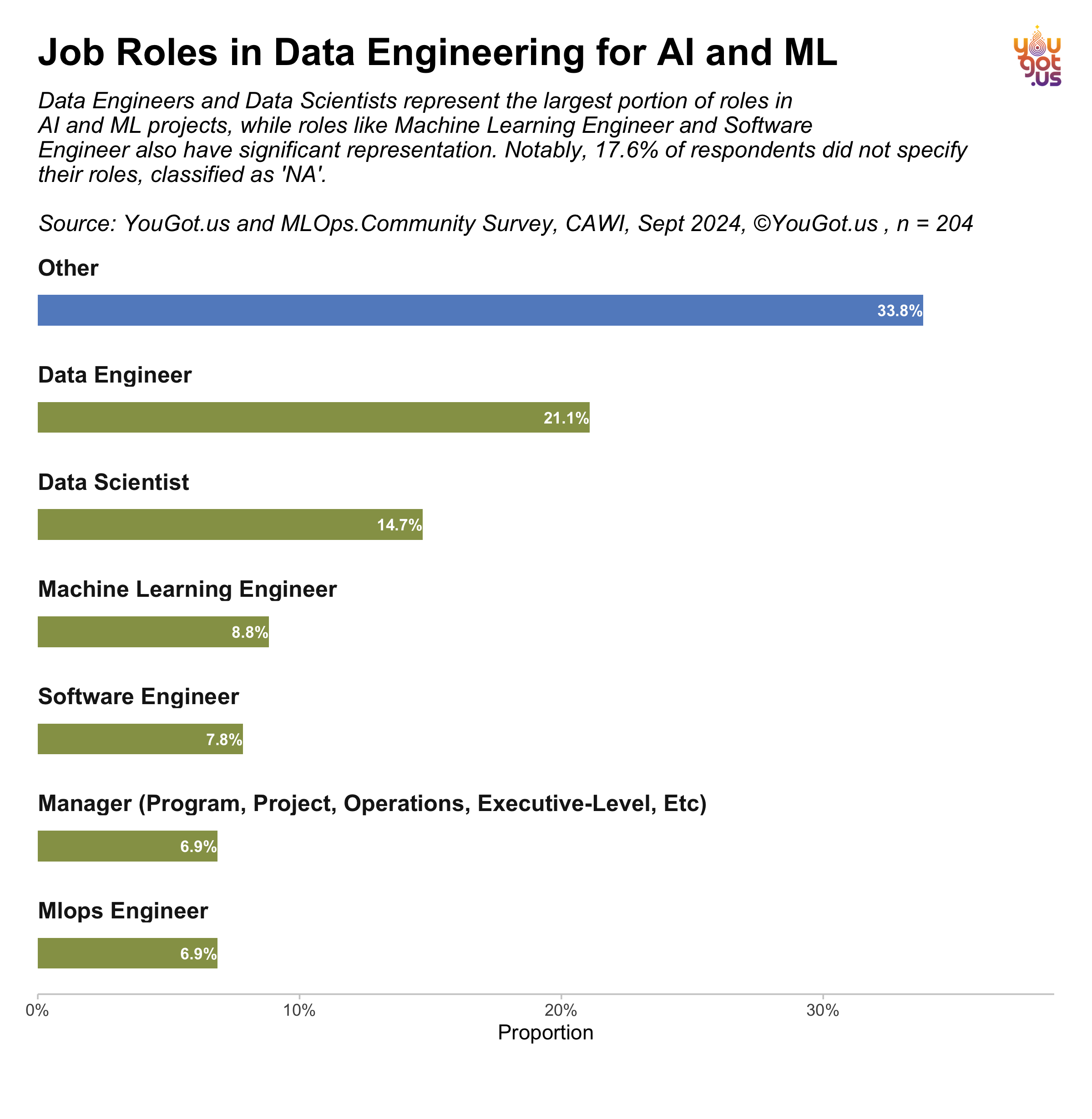
Interestingly, a significant portion of respondents (33.8%) classified their roles as “Other,” highlighting the diverse nature of job titles in this space. Additionally, 6.9% of respondents identified as MLOps Engineers, and another 6.9% hold various management roles, including program and project managers, as well as executive-level positions. Notably, 17.6% of participants chose not to specify their roles, marked as “NA” in the survey data.
These findings reflect the varied landscape of data engineering roles within AI and ML, showing a mix of specialized technical positions and broader managerial roles. The high percentage of “Other” responses suggests that job titles and responsibilities in this field are continuing to evolve.
Promising AI Talent Pipeline: Age Distribution in Data Engineering for AI/ML
A significant proportion of data engineers contributing to AI/ML projects are in the age groups of 25-29 and 30-34, each accounting for 21.1% of respondents, according to a survey conducted in September 2024 by YouGot.us and the MLOps Community. This suggests a strong presence of professionals in their mid-20s to early-30s, often at pivotal stages of career growth in the field of AI and machine learning.
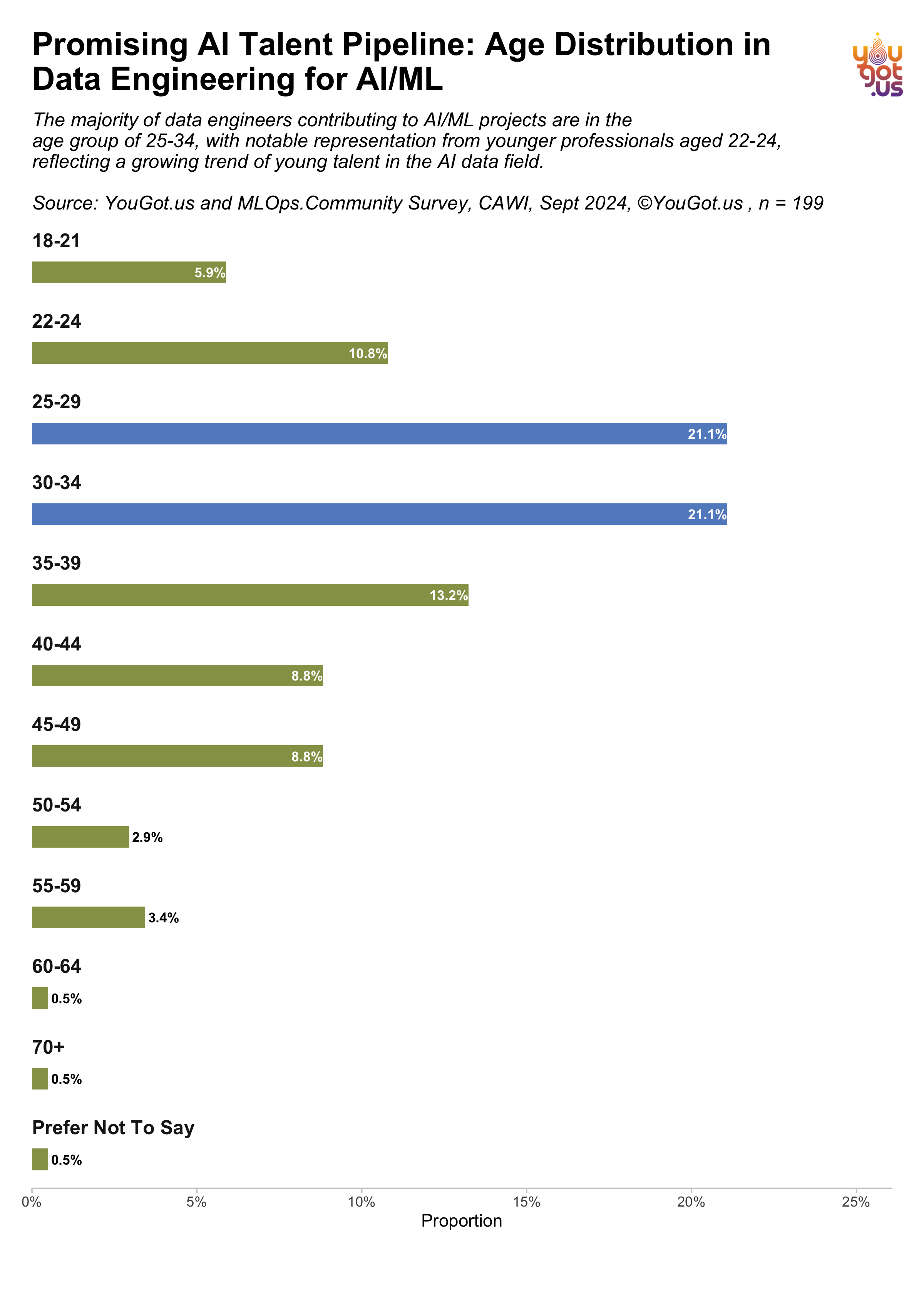
Additionally, younger professionals aged 22-24 make up 10.8% of the respondents, indicating a growing influx of early-career talent into data engineering roles. While the majority of participants fall between the ages of 25 and 39, with 13.2% in the 35-39 age group, there is also notable representation in older age categories, including 8.8% in both the 40-44 and 45-49 ranges.
The survey highlights the diversity in age groups contributing to AI/ML projects, suggesting that professionals at various stages of their careers are engaging in data engineering work. With the distribution skewed toward younger professionals, the data reflects a promising talent pipeline for the AI/ML field.
Team Sizes Responsible for ML/Data Science Workflows
According to the YouGot.us and MLOps Community Survey conducted in September 2024, most organizations have teams of 3-9 individuals responsible for managing ML and data science workflows. Specifically, 13.7% of respondents reported team sizes of 3-4 individuals, and another 13.7% reported teams of 5-9 individuals. Smaller teams consisting of 1-2 people also play a significant role, representing 9.3% of the responses.
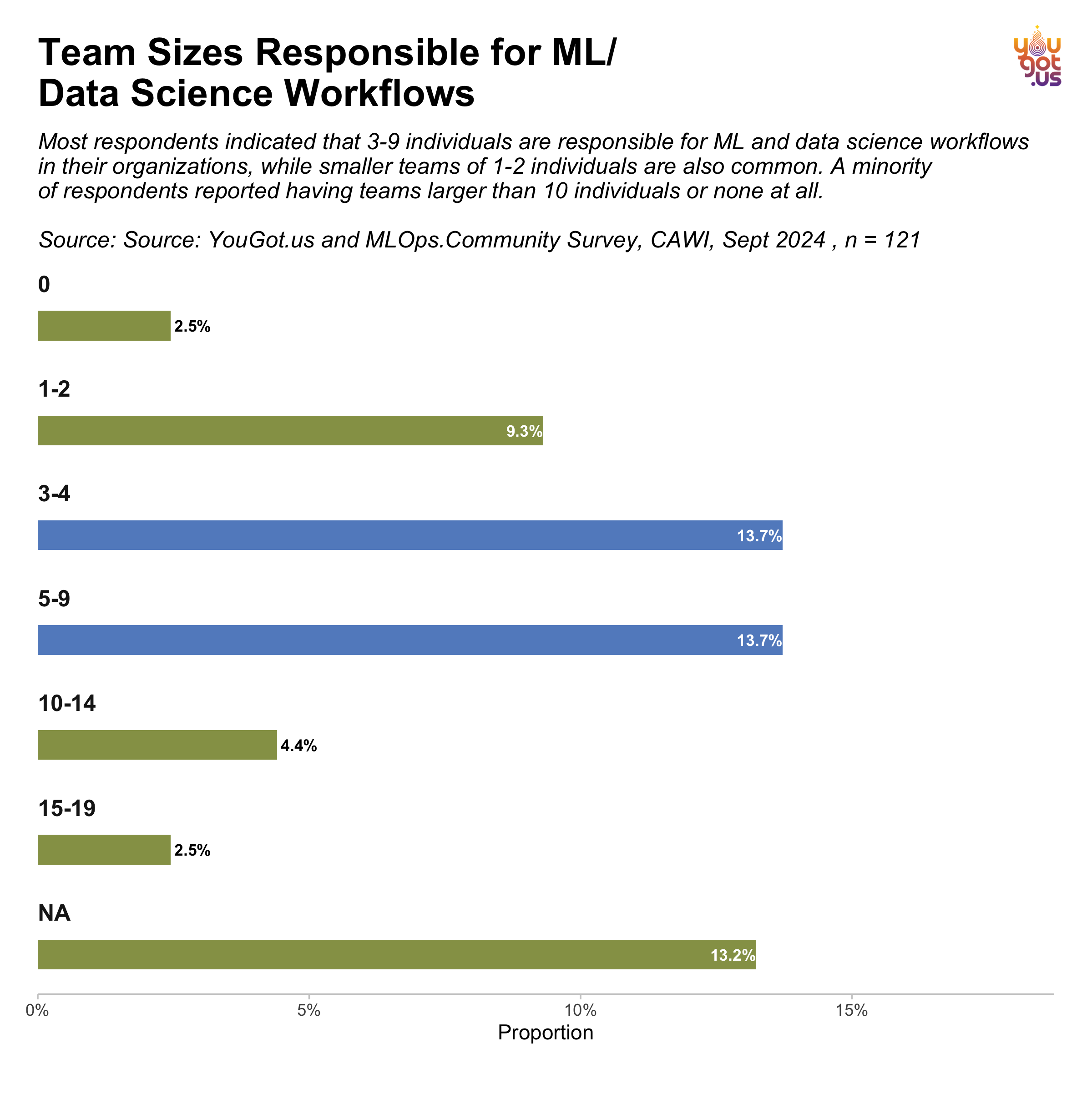
While a minority of organizations reported larger teams, with 4.4% indicating team sizes of 10-14 and 2.5% reporting 15-19 individuals, there are also organizations where no dedicated team is responsible (2.5%). Additionally, 13.2% of respondents did not specify the size of their teams.
These findings suggest that most ML and data science workflows are managed by relatively small teams, typically fewer than 10 individuals, reflecting a lean but effective approach in many organizations.
Challenges in Coordinating Across Teams or Individuals When Building Pipelines
Among the 204 respondents, the most common issue was the difficulty in ensuring clear and consistent communication across teams or individuals, reported by 24.5% of respondents. This suggests that communication breakdowns are a major hurdle in collaborative ML and data engineering projects.
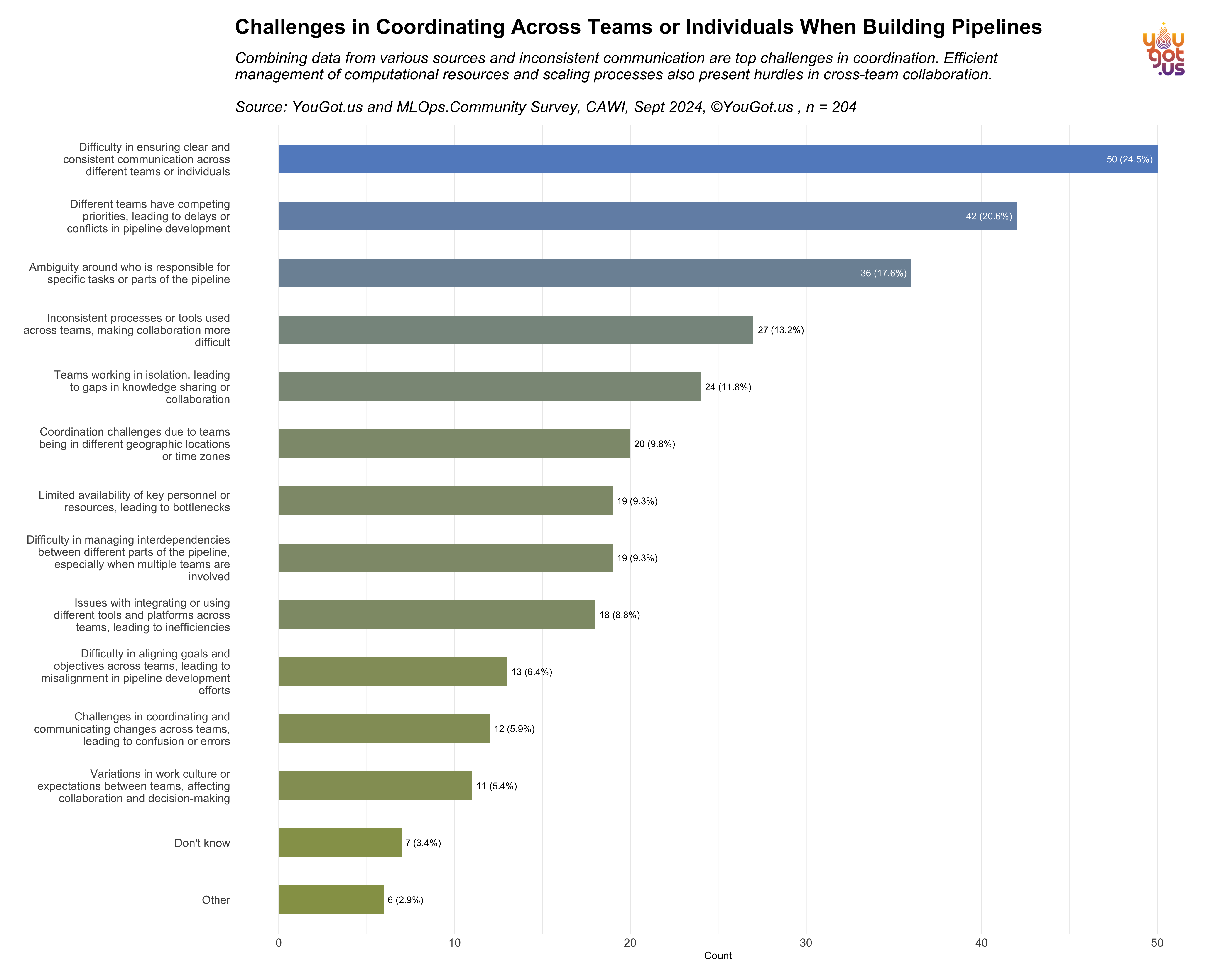
Other significant challenges include different teams having competing priorities, cited by 20.6% of respondents, which often leads to delays or conflicts during pipeline development. Additionally, ambiguity around responsibilities for specific tasks was noted by 17.6%, emphasizing the need for more defined roles and ownership in pipeline workflows.
Inconsistent tools or processes used across teams (13.2%) and isolation in knowledge sharing (11.8%) were also identified as key barriers to effective collaboration. Furthermore, geographical or time zone differences (8.8%) and limited availability of personnel or resources (9.3%) contribute to coordination difficulties.
Other challenges involve managing interdependencies between different pipeline parts (9.3%) and issues with integrating or using disparate tools (8.8%), further complicating cross-team efforts. A smaller portion of respondents reported alignment difficulties in goals or objectives (6.4%) and variances in work culture (5.4%).
The findings suggest that while communication and coordination are critical to success in AI/ML pipeline development, diverse teams face significant structural and operational barriers that must be addressed to improve efficiency and effectiveness in large-scale collaborative projects.
Who Is Primarily Responsible for Designing and Maintaining Data and ML Pipelines?
According to a survey conducted by YouGot.us and the MLOps Community in September 2024, Data Engineers are the primary individuals responsible for managing and maintaining ML/AI pipelines, with 27.5% of respondents indicating this role. Data Scientists follow, with 10.3% of respondents reporting that their organizations assign them this responsibility.
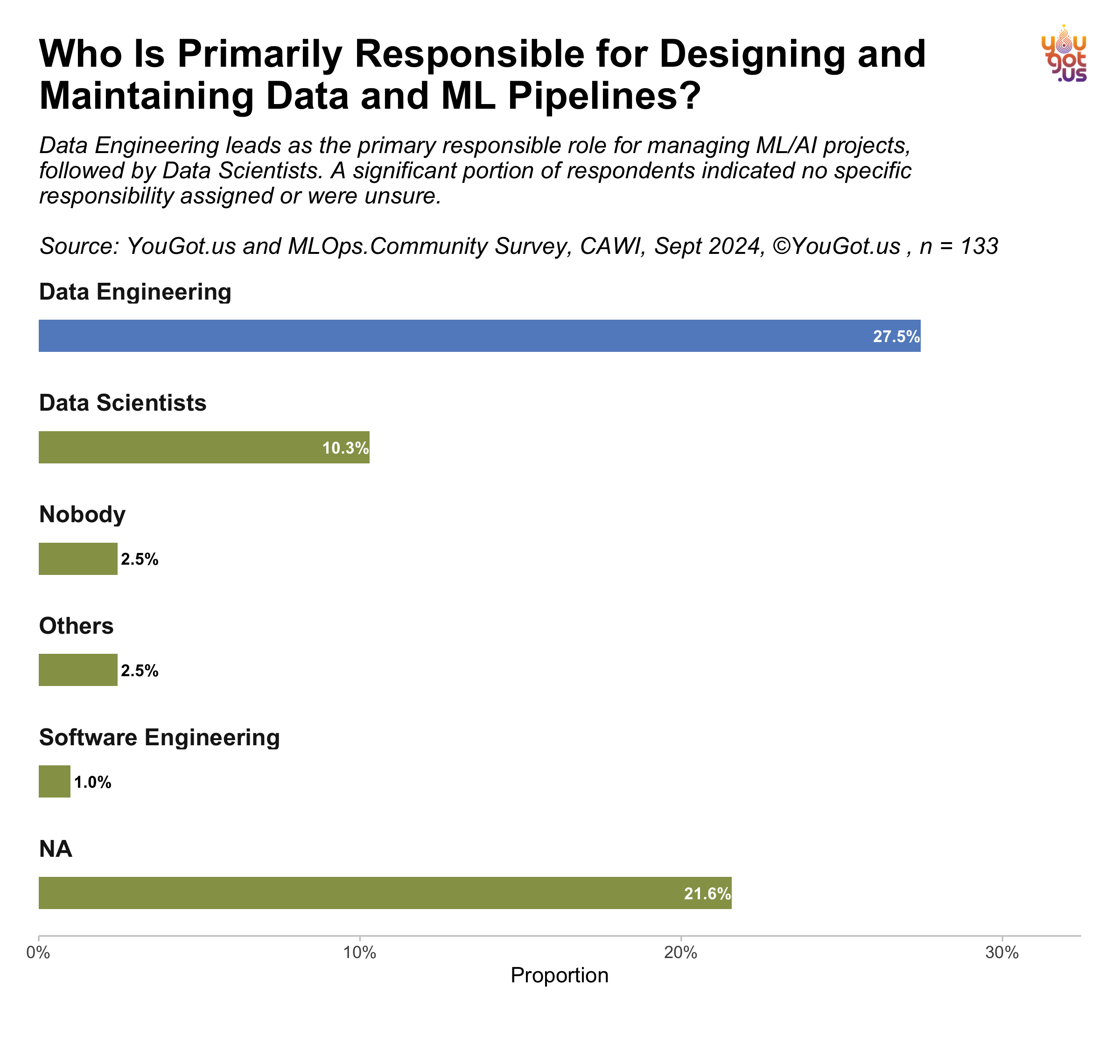
Interestingly, a significant portion of participants (21.6%) marked their response as “NA,” suggesting that many organizations either have unclear responsibility structures or that the role varies. A small percentage of respondents indicated that nobody (2.5%) is specifically assigned to manage pipelines, highlighting gaps in organizational structures for some teams. Other roles such as Software Engineering (1%) and miscellaneous “Others” (2.5%) also appear to take responsibility in certain cases.
These results underscore the central role that Data Engineers play in the development and upkeep of machine learning pipelines, though the distribution of responsibility shows that, in some organizations, this task may still be shared or remain ambiguous.
Collaboration and Responsibility Structures in ML/AI Pipelines
The most common approach to managing ML/AI pipelines, according to a survey by YouGot.us and the MLOps Community in September 2024, is collaboration across multiple teams. 13.7% of respondents reported that their organizations utilize this cross-team collaboration model, where various teams work together on different parts of the pipeline.
Other respondents (12.7%) indicated that specific teams handle distinct parts of the pipeline, suggesting a more compartmentalized approach to managing ML/AI workflows. Furthermore, 7.8% reported that roles are explicitly assigned to Data Engineers and ML Engineers, emphasizing structured, role-based management.
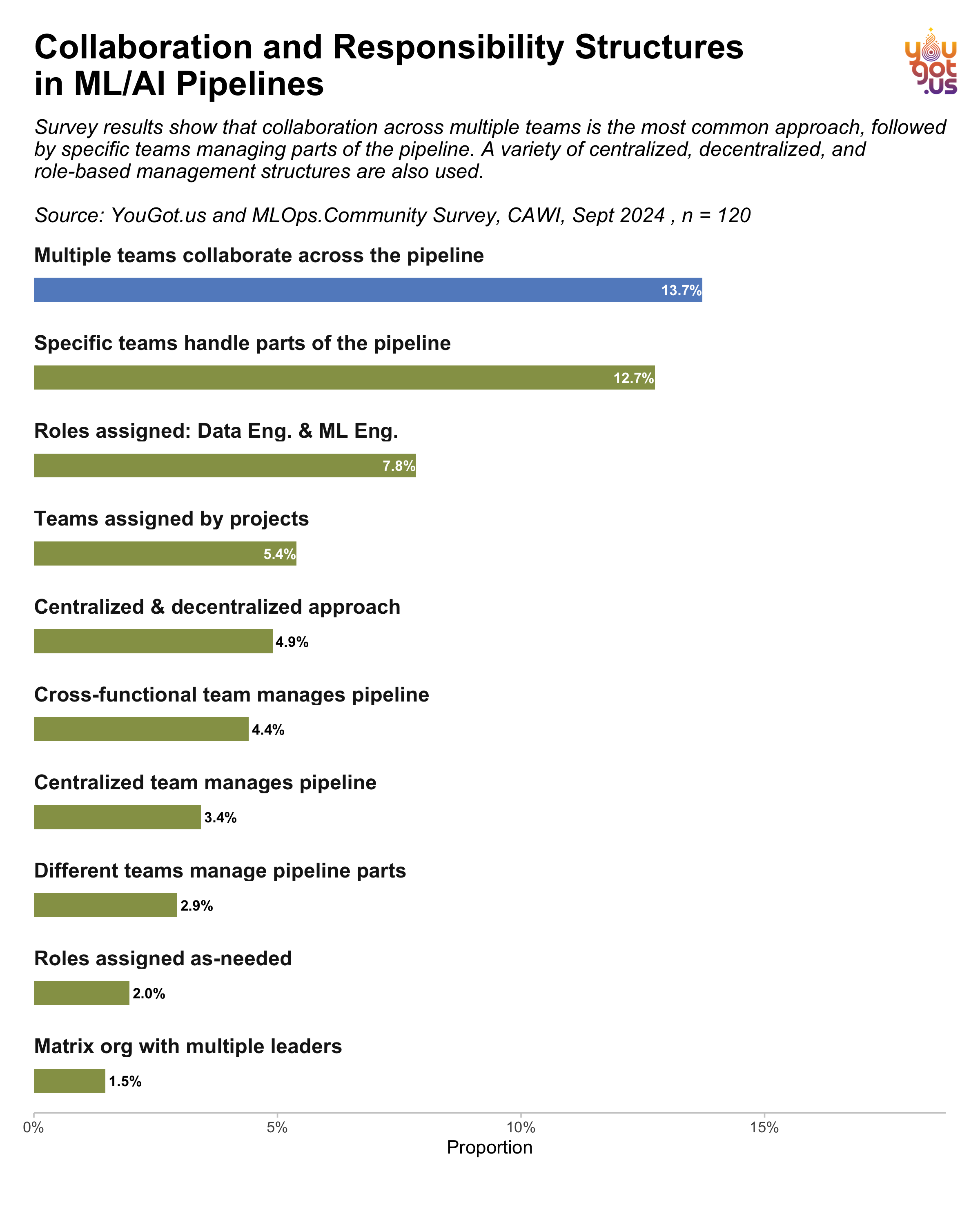
Additional collaboration structures include teams assigned by projects (5.4%) and a centralized & decentralized hybrid approach (4.9%). Cross-functional teams are also employed by some organizations, with 4.4% of respondents noting that these teams take responsibility for the entire pipeline. Centralized teams are less commonly used, with only 3.4% indicating this approach.
Some respondents noted more flexible or informal management strategies, including roles assigned on an as-needed basis (2%) and a matrix organization with multiple leaders (1.5%).
These results highlight the diversity of collaboration structures in managing ML/AI pipelines, ranging from centralized teams to decentralized and cross-functional models, with collaboration across multiple teams being the most prevalent.
State of Data Tools for AI and ML
(Register and get notified when it becomes available)
Adoption of Data and ML Orchestration Tools
(Register and get notified when it becomes available)
Team Dynamics in AI/ML Projects
(Register and get notified when it becomes available)
Conclusions
(Register and get notified when it becomes available)
About MLOps Community and YouGot.us
YouGot.us is a distinguished organization focusing on AI/ML and Data Science industries. Known for its thorough data research projects and perceptive analyses, it stands as a premier resource for research initiatives in the emerging Generative AI business place. The MLOps Community, a pivotal partner of YouGot.us, stands at the forefront of addressing the growing importance of MLOps, distinct yet parallel to DevOps, by facilitating the exchange of real-world best practices among professionals in the arena.
Citation
@online{garcia2024,
author = {Garcia, Christina},
title = {Data {Engineering} for {AI}},
date = {2024-11-09},
url = {https://yougot.us/news/2024-11-09-Data-Engineering-for-AI/},
langid = {en}
}